
原文标题:Darknet traffic classification and adversarial attacks using machine learning
原文作者:Nhien Rust-Nguyen, Shruti Sharma and Mark Stamp
原文链接:https://www.sciencedirect.com/science/article/pii/S0167404823000081
数据集:https://www.unb.ca/cic/datasets/darknet2020.html
发表期刊:Computers & Security
笔记作者:孙汉林@安全学术圈
1、引言
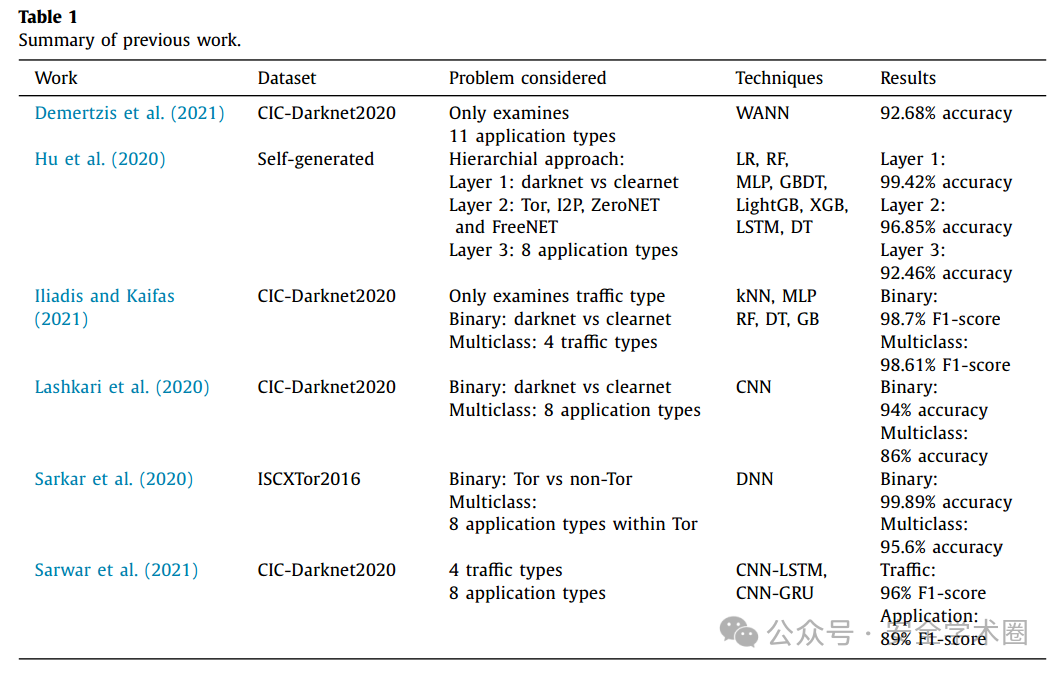 本文通过评估多种机器学习和深度学习算法,来提高暗网流量及其底层应用类型的检测效果。作者基于前人的研究(如上图所示),选择了CIC-Darknet2020数据集,并由实验得出,随机森林(Random Forest)的表现最优。为了评估RF的鲁棒性,作者增加了额外对抗攻击实验,通过混淆部分应用类型流量来模拟真实的对抗攻击场景。结果表明,RF在面对这些对抗攻击时性能有所下降,同时,作者也讨论了如何有效应对这种攻击。
本文通过评估多种机器学习和深度学习算法,来提高暗网流量及其底层应用类型的检测效果。作者基于前人的研究(如上图所示),选择了CIC-Darknet2020数据集,并由实验得出,随机森林(Random Forest)的表现最优。为了评估RF的鲁棒性,作者增加了额外对抗攻击实验,通过混淆部分应用类型流量来模拟真实的对抗攻击场景。结果表明,RF在面对这些对抗攻击时性能有所下降,同时,作者也讨论了如何有效应对这种攻击。2、实验方案

本文选取了多种机器学习和深度学习算法,包括支持向量机(SVM)、随机森林(RF)、梯度提升决策树(GBDT)、极端梯度提升(XGBoost)、k近邻(k-NN)、多层感知机(MLP)、卷积神经网络(CNN)以及辅助分类生成对抗网络(AC-GAN)。实验流程如下:
数据增强:在预处理阶段应用SMOTE方法,对CIC-Darknet2020数据集中的少数类别进行过采样,以评估数据增强和类别平衡对分类器性能的影响。尽管还尝试使用AC-GAN生成器进行数据增强,但发现其效果不佳。 特征表示:将暗网流量特征表示为二维灰度图像,用于CNN和AC-GAN模型的分类实验。 对抗性攻击模拟:测试随机森林在不同混淆场景下的鲁棒性,模拟对抗性攻击。分三种场景测试:仅混淆验证数据、仅混淆训练数据、以及同时混淆训练和验证数据。探讨攻击者通过数据混淆伪装类别的影响,以及防御者通过更新分类器恢复性能的策略。
对于深度学习算法,实验方案如下:
3、数据集
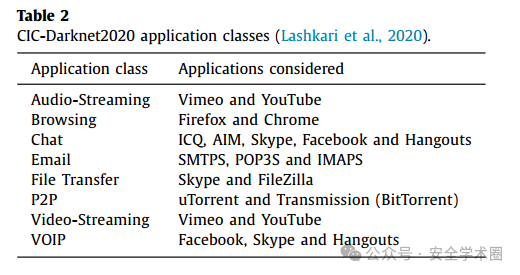
本文使用的CIC-Darknet 2020数据集是由新布伦瑞克大学的两个公开数据集 ISCXTor 2016 和 ISCXVPN 2016 合并而成的。该数据集共包含158,659个样本,分为两级标签:
一级标签:Tor、非Tor、VPN、非VPN。 二级标签:音频流媒体、浏览、聊天、电子邮件、文件传输、P2P、视频流媒体、VOIP。 具体数量如下图所示: 
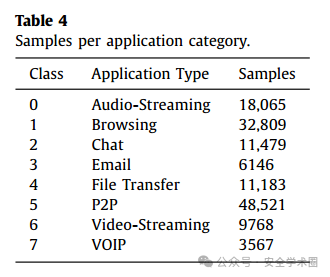 从图中可知,数据集中各类别样本数量差异显著,例如:样本最多的类别(P2P)有 48,521 条记录。样本最少的类别(VOIP)仅有 3,567 条记录。数据存在严重的不平衡现象,可能会对检测结果产生影响。
从图中可知,数据集中各类别样本数量差异显著,例如:样本最多的类别(P2P)有 48,521 条记录。样本最少的类别(VOIP)仅有 3,567 条记录。数据存在严重的不平衡现象,可能会对检测结果产生影响。
3.1 数据增强
为了应对 CIC-Darknet 2020 数据集中应用类别样本数量不平衡的问题,研究采用了 SMOTE(合成少数类过采样技术)来平衡数据。SMOTE 通过在少数类别样本的特征值之间进行线性插值,生成新的合成样本,从而增加少数类别的样本数量。
本文按拥有最大样本数的类别(P2P)数量作为基准,过设置采样比例,将样本数量较少的类别数增加到目标比例。如采样比例为100%,则将所有类别的样本数量均增加至48,521个,即P2P的样本数量。
通过应用 SMOTE ,作者在不同平衡水平下评估了数据不平衡对分类结果的影响,为实现更精准的暗网流量分类提供了基础数据支持。
3.2 数据表示
在实验中,不同模型对 CIC-Darknet2020 数据集的数据表示方式不同,为适配分类器的需求,进行了以下处理:
SVM、RF 等传统机器学习模型:使用数据的原始格式,即 1 维数组,每个样本由72个特征组成。
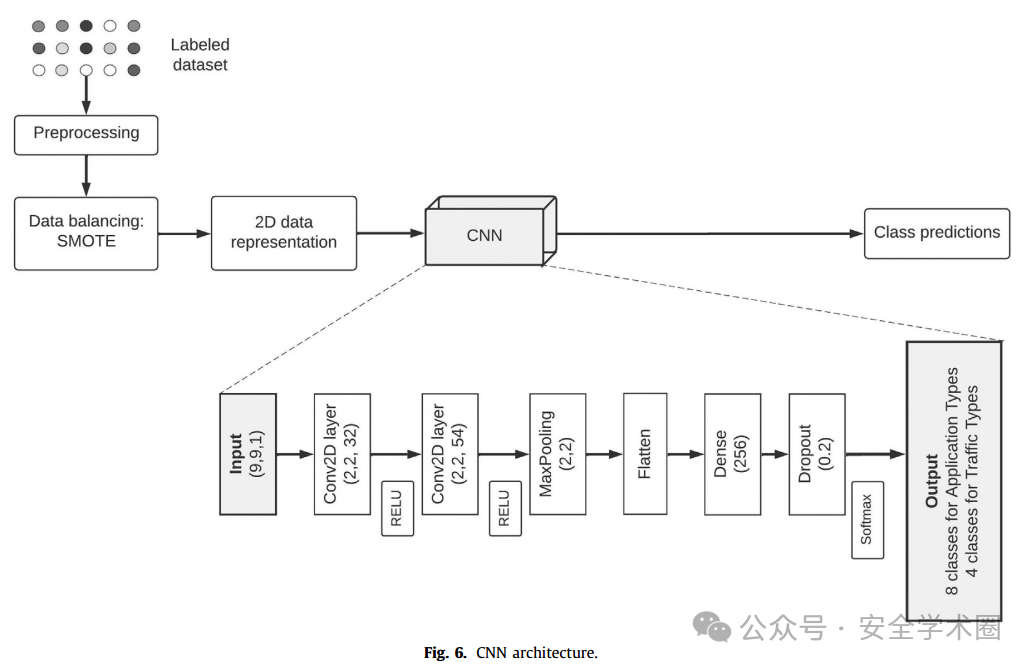
CNN 和 AC-GAN 深度学习模型:将数据被转换为 9×9 的灰度图(72个特征分别映射到72个像素),剩余的像素通过零填充补齐。使每个样本整形为2维灰度图。如下图所示。
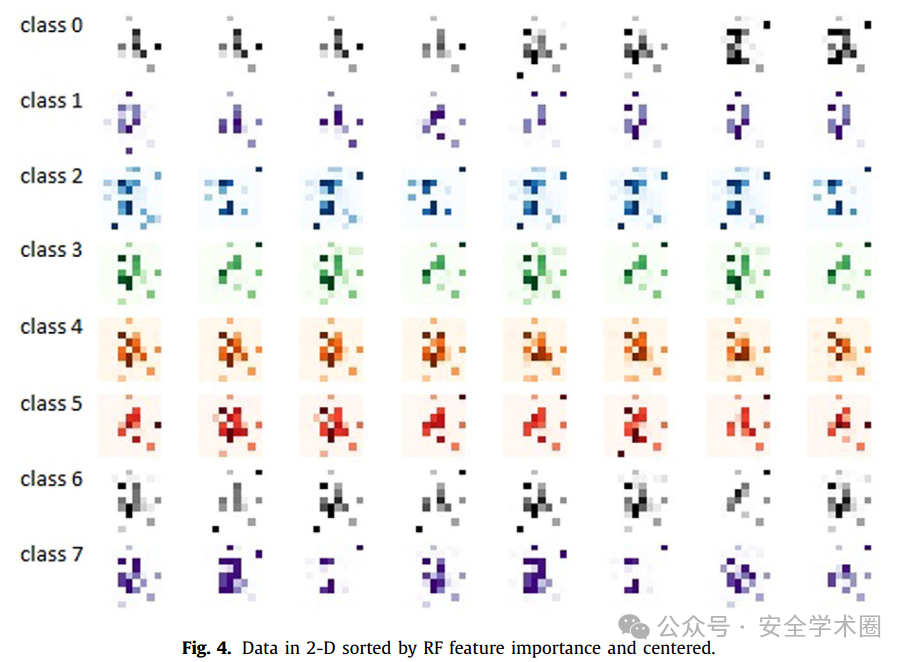
由于CNN和AC-GAN都对二维图像中的局部结构进行卷积,因此相邻像素在分类中起着重要作用。因此,作者尝试了根据特征重要性,重新排序数据以实现更好的性能。
4、对抗攻击
特征混淆是通过修改样本中的特征值,使其原本属于一个类的样本表现得像另一个类的样本。混淆的目的是使分类器无法正确分类这些混淆过的样本。
本文通过特征混淆实现对抗攻击,通过计算各个类之间特征分布的统计距离,决定哪些类应该伪装成其他类。计算结果如下图所示:
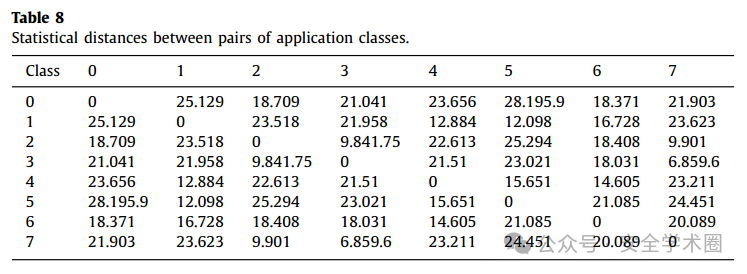
观察特征分布的差异,选择最相似和最不同的类进行混淆。即,类 3(电子邮件)与类 7(VOIP)进行混淆(最相似);类 0(音频流)与类 5(P2P)进行混淆(最不同)。
除此之外,作者还利用RF的混淆矩阵得出,RF在类2(聊天)和类3(电子邮件)之间最容易混淆,因此作者添加了类2与类3的混淆情况。即共3种混淆类:类3与类7(统计距离)、类0与类5(统计距离)、类2与类3(混淆矩阵)。
本文将对抗攻击场景分为3种:
Scenario1:在训练集中添加混淆数据; Scenario2:在测试集中添加混淆数据; Scenario3:在训练集和测试集中添加混淆数据。
5、实验结果
不同比例的数据增强情况下,各个模型的暗网流量分类与应用分类效果如下图所示: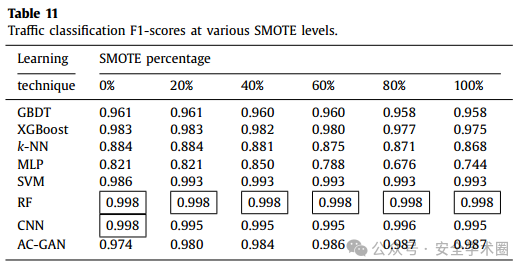
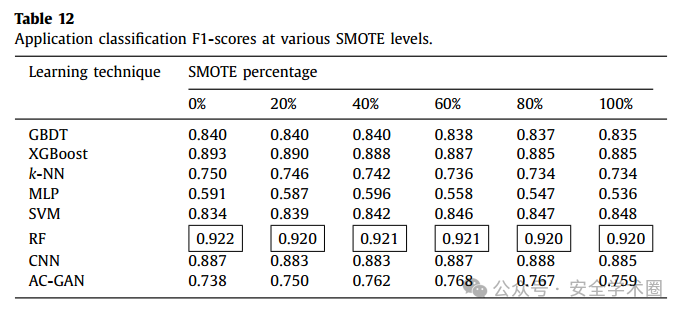
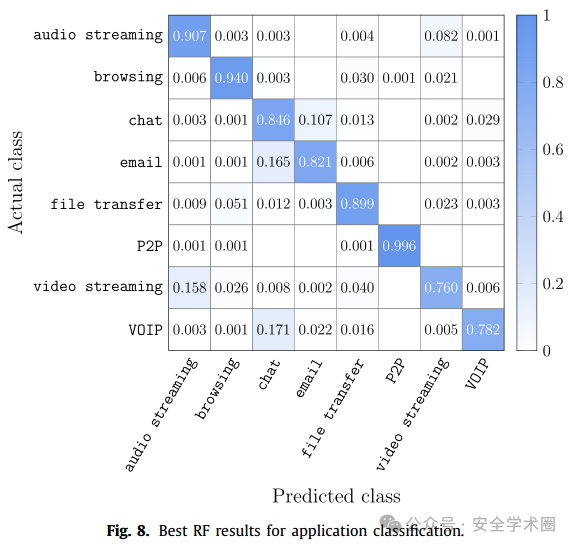
不同对抗攻击场景下,RF分类器的表现如下图所示:
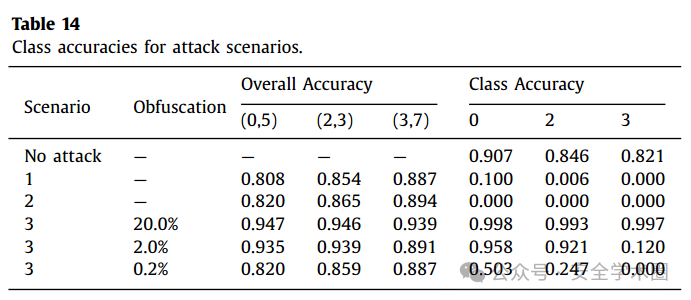
本文通过多分类器对CIC-Darknet2020数据集进行深入研究,发现随机森林在流量和应用分类中表现最佳。对抗攻击实验揭示了攻击者通过修改流量特征显著降低分类器准确性的可能性,但 RF 分类器通过增加训练数据暴露量对混淆特征表现出较强的适应性。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
专题最新征文
期刊征文 | 暗网抑制前沿进展 (中文核心)
期刊征文 | 网络攻击分析与研判 (CCF T2)
期刊征文 | 域名安全评估与风险预警 (CCF T2)